今天装好了一个三节点的Hadoop。参考这两篇文章[1]和[2]。中文参考文档虽然详细,但是有些错误。记录我的安装步骤如下。
1.三个节点服务器安装CentOS7.2最小版,配置各节点无密码ssh登录(参考前几天的文章)。
2.在每个节点上安装JDK。在Oracle.com官网上注册,然后下载jdk-7u45-linux-x64.rpm,在每个节点上安装JDK并执行以下命令,用rpm安装后java的路径为“/usr/java/jdk1.7.0_45”。以node333为例:
# rpm -ivh jdk-7u45-linux-x64.rpm
# vim /etc/profile (修改配置文件,增加以下行)
export JRE_HOME=/usr/java/jdk1.7.0_45/jre
export JAVA_HOME=/usr/java/jdk1.7.0_45/
export CLASSPATH=$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
# source /etc/profile (使配置文件生效)
# java -version (检查安装是否成功)
java version "1.7.0_45"
Java(TM) SE Runtime Environment (build 1.7.0_45-b18)
Java HotSpot(TM) 64-Bit Server VM (build 24.45-b08, mixed mode)
3.在节点node333,下载hadoop-2.10.0.tar.gz并解压到/usr下
# ls /usr/hadoop-2.10.0/
4.在节点node333,参考文档[2]配置hadoop。首先配置core-site.xml文件(注意将原文件备件),此次试验将node333设置为集群的namenode。
# cd /usr/hadoop-2.10.0/etc/hadoop
# vim core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://node333:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop_tmp</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
</configuration>
其次配置hdfs-site.xml文件(文件路径都在/usr/hadoop-2.10.0/etc/hadoop),设置副本数为“2”(默认为3?)。
# vim hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
</configuration>
接着配置mapred-site.xml文件,目录中没有这个文件,需要先根据模板生成。将node555设置为SecondaryNameNode。
# cp mapred-site.xml.template mapred-site.xml
# vim mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node555:50090</value>
</property>
</configuration>
然后配置yarn-site.xml,YARN即Yet Another Resource Negotiator的缩写,是一个资源管理系统。将node444设置为resourcemanager。
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node444</value>
</property>
</configuration>
接着配置slaves文件,将各节点主机名加入:
# vim slaves
node333
node444
node555
在hadoop-env.sh中配置JAVA_HOME的路径
# vim hadoop-env.sh (修改对应行)
export JAVA_HOME=/usr/java/jdk1.7.0_45/
最后再次配置/etc/profile 加入HADOOP_HOME执行路径:
# vim /etc/profile
export JRE_HOME=/usr/java/jdk1.7.0_45/jre
export JAVA_HOME=/usr/java/jdk1.7.0_45/
export HADOOP_HOME=/usr/hadoop-2.10.0/
export CLASSPATH=$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
# source /etc/profile
所有配置完成。
5.在node333上检查已经安装成功,可以显示正确的hadoop版本信息。
# hadoop version
Hadoop 2.10.0
Subversion ssh://git.corp.linkedin.com:29418/hadoop/hadoop.git -r
e2f1f118e465e787d8567dfa6e2f3b72a0eb9194
Compiled by jhung on 2019-10-22T19:10Z
Compiled with protoc 2.5.0
From source with checksum 7b2d8877c5ce8c9a2cca5c7e81aa4026
This command was run using /usr/hadoop-2.10.0/share/hadoop/common/hadoop-common-2.10.0.jar
6.在node333上,将hadoop文件目录和profile文件复制到其它节点(node444和node555)
# scp -r hadoop-2.10.0 root@node444:/usr/
# scp -r hadoop-2.10.0 root@node555:/usr/
# scp profile root@node444:/etc/
# scp profile root@node555:/etc/
我在之前的测试中,早早在各节点中解压了hadoop目录,没有同步配置文件,导致node333启动hadoop服务后没有找到数据节点。有些大意了。
在node444和node555上分别执行以下命令,使路径生效。
# source /etc/profile
7.启动hadoop。在node333(已设置为Name Node)上做初始化。
# hadoop namenode -format
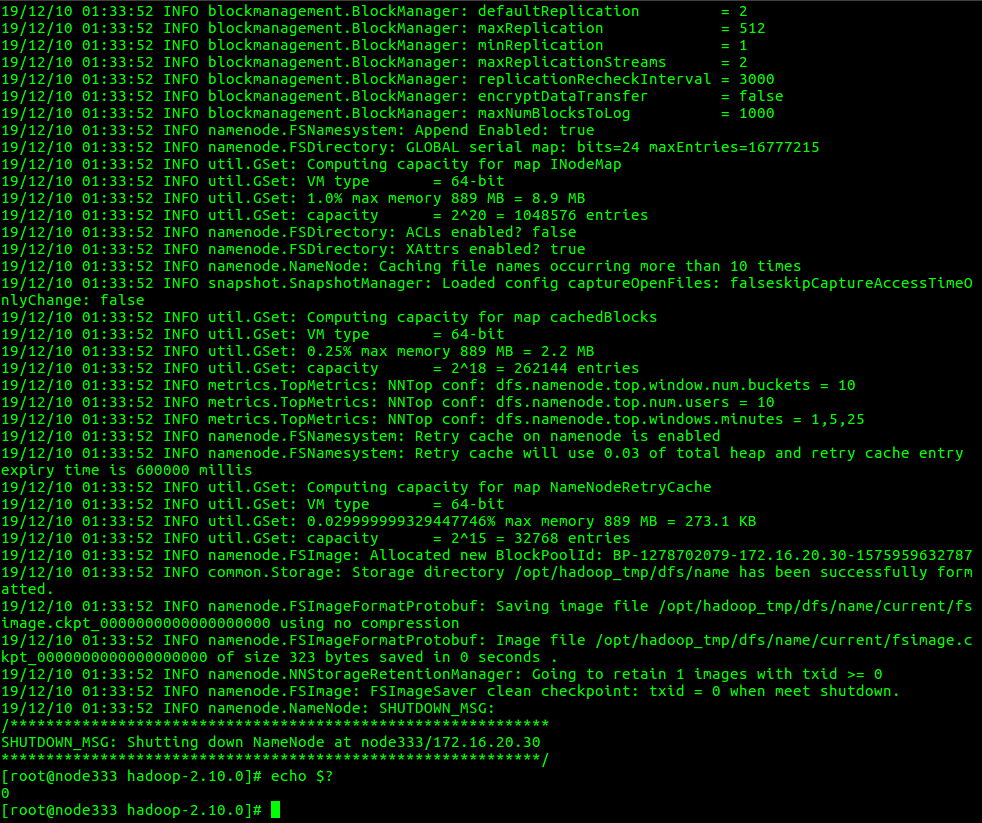
启动hdfs,在hadoop下的sbin下:
# ./start-dfs.sh
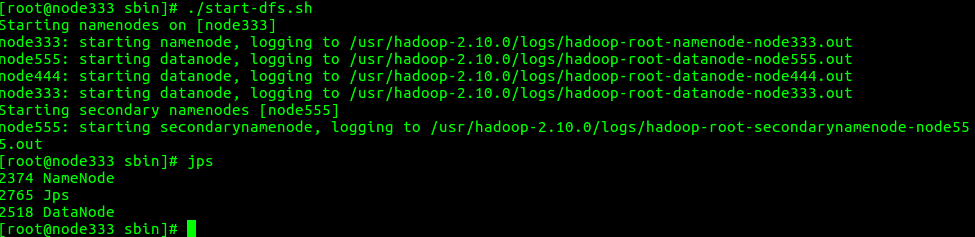
在各节点上执行jps可以看到如下结果:
[root@node333 ~]# jps
7735 Jps
2618 NameNode
[root@node444 ~]# jps
2418 Jps
2207 DataNode
[root@node555 ~]# jps
10192 SecondaryNameNode
10086 DataNode
10526 Jps
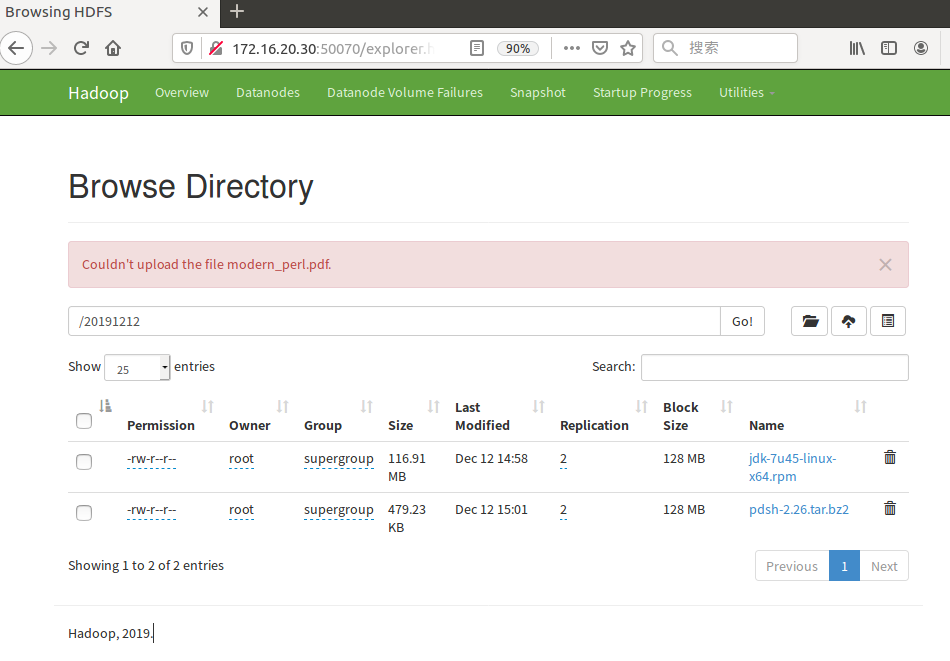
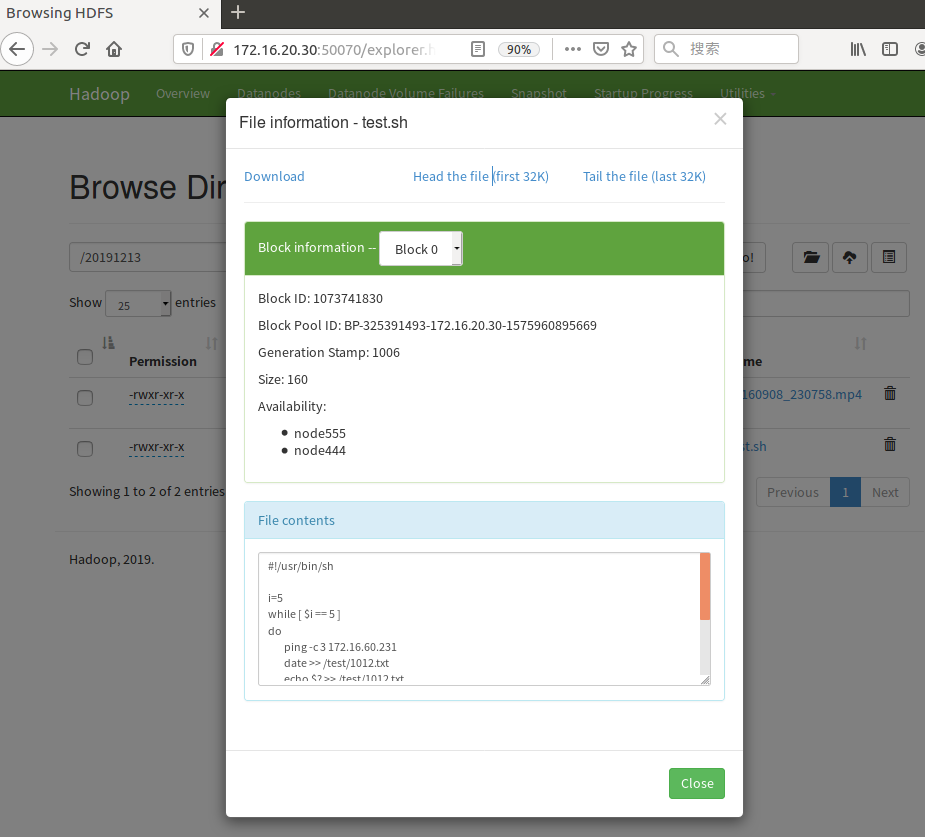
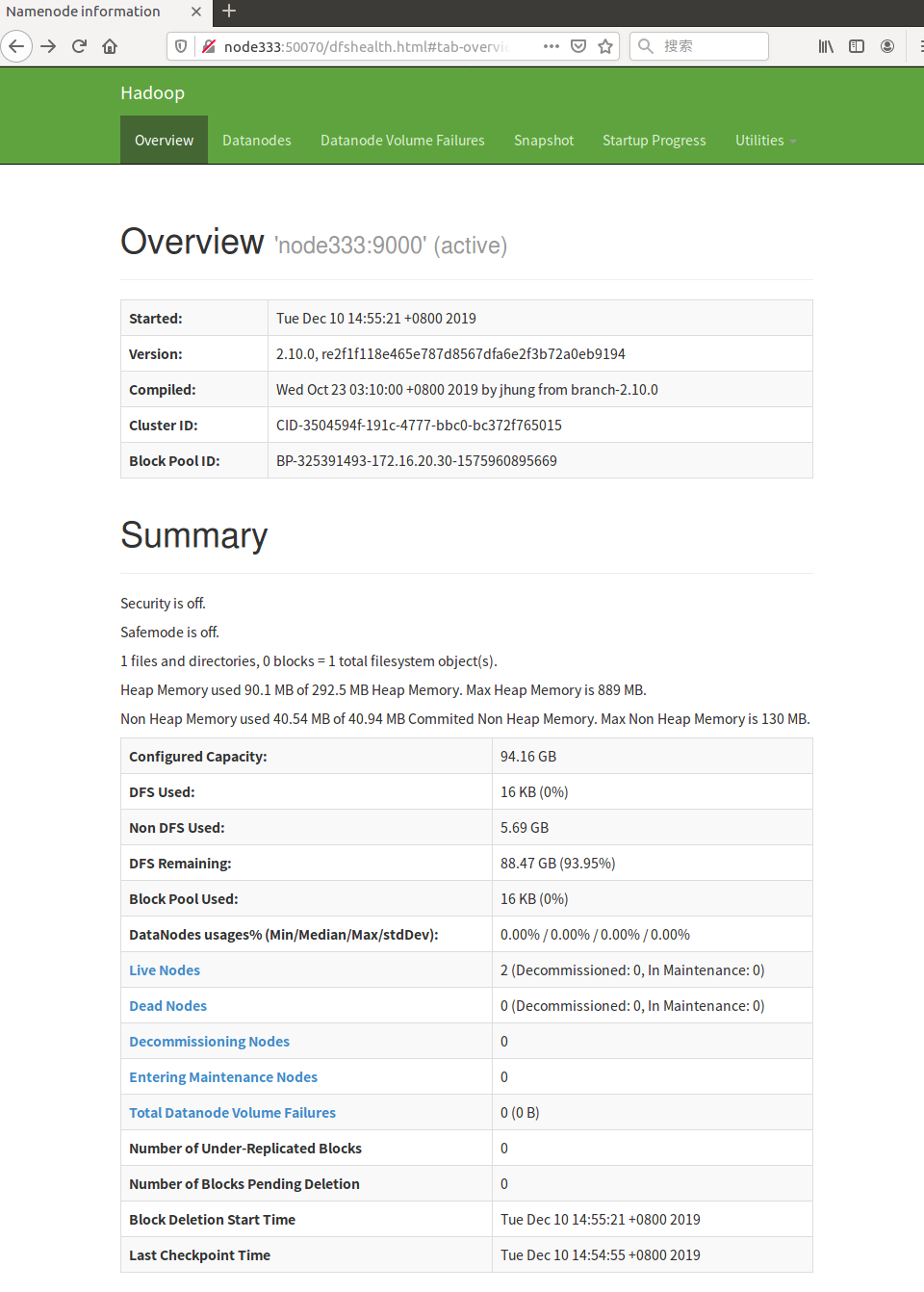
8.在浏览器中访问集群,可以看到各节点状态。
DataNode列表
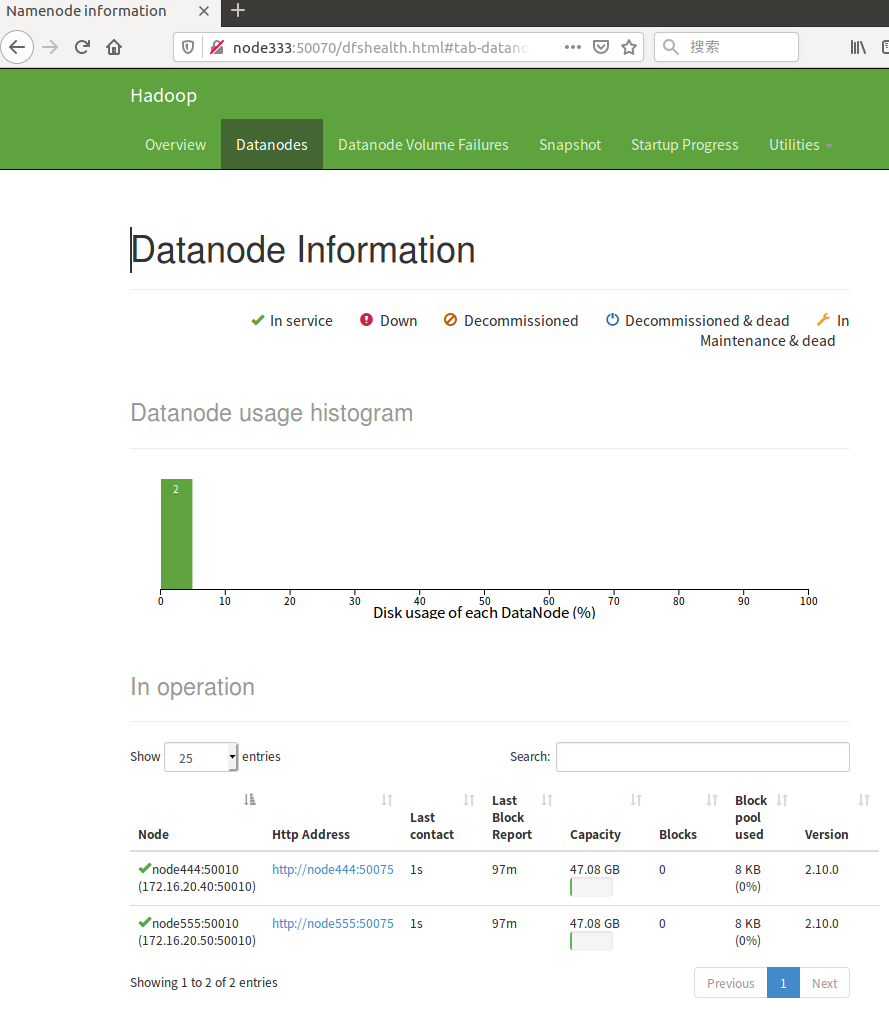
遗留问题,每个节点还有三块硬盘。这些未挂载未格式化的硬盘容量未体现在集群中,下一步解决。